数据源与多数据源
报表的使用者常常需要了解某些动态的内容,这些动态的内容可能是银行卡帐户的交易信息,也可能是电力设备上的负荷信息,也可能税务机关的纳税欠税信息,等等。
报表的动态内容从什么地方来?是否过滤?是否排序?这些参数需要我们报表设计者在设计报表时指定。例如,如果报表中的数据来自数据库(jdbc),则需要指定数据库服务器的位置、用户名、口令和sql查询等。这些动态内容,称之为数据源,这些动态内容的配置过程,称为数据源配置。
如果一个报表的动态部分,由若干个数据源构成,则称之为多数据源报表。如主从报表,主表的信息可能是一个班级表,从表的信息,可能是这个班级的学生名册表。
数据源与数据集
数据集是指二维结构的数据集合,由若干行,若干列的数据组成,每列有列名,有列数据类型。数据集可以从数据源中得到,而且,可能不至一个,从这个意义上说,数据源更像是数据集的容器。
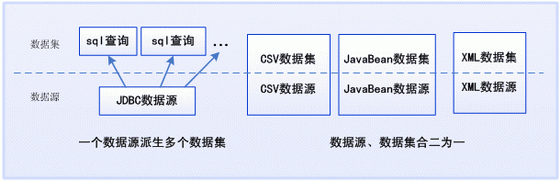
对于jdbc来说,我们把连接到一个目标数据库的对象,称为数据源,把针对这个连接得到的查询,称之为数据集。但有些数据集并没有一个明确的数据源对象,比如csv数据集,这类数据集只需要设置一个csv文件路径,不同的csv数据集,只能通过设置不同的文件路径获得。实际上,我们仍然可以认为,csv数据集中存在一个csv数据源,而且,这个csv数据源只能得到一个csv数据集。总之,对csv而言,数据集就是数据源,反之亦然。
根据我们的理解,报表厂商宣讲的多数据源报表,实际上,讲的是这个报表可以有多个数据集,所以,将多数据源报表称为多数据集报表,更为准确。如,一个主从报表,其主表数据集,和从表数据集,都来自同一数据库(数据源),但这个报表也通常被认为是多数据源报表。
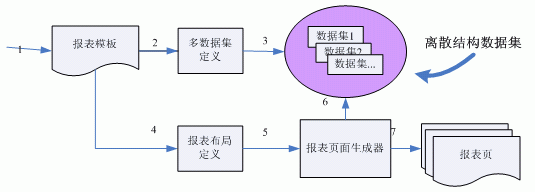
多数据集的离散结构
早期的报表工具在解析一个多数据集的报表模板时,常常将这些数据集是置于一个报表计算引擎的离散结构中,如下图所示:
如果数据集之间确实存在关系,以下两个解决办法:内过滤法,外过滤法。下面我们以主从报表,jdbc数据源为例,说明这两类方法,
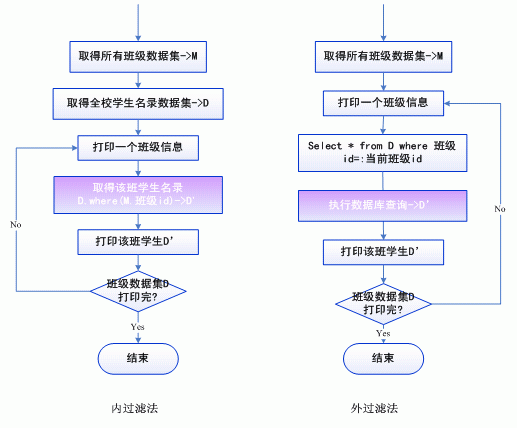
内过滤法,即在报表解析之前不仅需要取得主表数据集M,还需要取得从表数据集D,当需要特定班级的学生数据集D’时,通过对D数据集对象的过滤方法,如 D.where(班级id=:班级id)得到。
外过滤法,也需要先得到主数据集M,但特定班级的数据集D’是通过对数据库的查询得到,即主数据集有多少行,就需要查询多少次从数据集。
内过滤法的优点是效率高,因为不需要多次查询数据库,缺点是比较占用内存资源,在进行复杂查询时不能利用数据库本身的查询优化功能。外过滤法的优点是占用资源少,但多次连接数据库,必然导致性能下降。
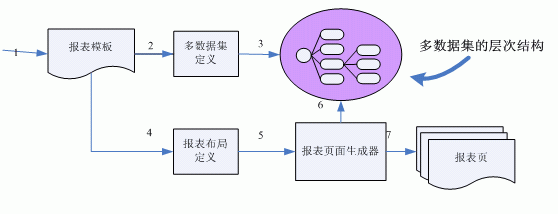
多数据集的层次结构
多数据集的层次结构,即是将多个数据集按其主从关系组织成一种树状结构,如下图所示,一个主表的某一行,对应一个从表数据集。
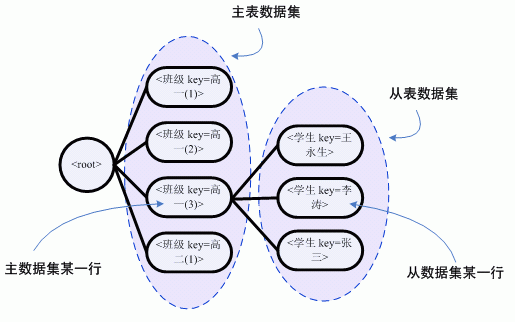
多数据集的层次结构,具有以下特点:
1. 数据集定义是直观的,是分层次的,有从属关系的;
2. 数据集是按需加载的(lazy loading);
3. 数据是全程可访问的,即在一个报表解析周期内任一时刻,都可访问到任何层次,任何节点的数据;
4. 可重用的;
5. 数据可以在多个报表解析任务中共享;
|
